Appearance
宋代官制书影信息抽取案例
历史研究官制研究OCR识别书籍图像抽取图片生成文本生成列表链式生成
| 【案例说明】本案例的目标是从《宋代官制大辞典》中提取某个官职的信息,包括官职名、设置时间、沿革、职掌、员额等信息。数据为书籍截图,简体字,一张图片。抽取过程为,先从原始图像中识别文字,再从文本中抽取信息。采用高级模式,实现链式生成。本案例说明了如何从图像当中抽取文本信息,并测试出了处理简体中文图像OCR任务效果较好的模型。 |
|---|
1. 任务目标
从《宋代官制大辞典》中提取“殿中省”这一官职的信息,包括官司或官吏名、设置时间、置废沿革、职掌沿革、官品沿革、员额、别称等,其中“官司或官吏名”以及“设置时间”抽取为文本数据,其它字段由于数量较多,抽取为列表。抽取时间时,需要抽取出朝代、年号、年份等信息。
2. 原始数据说明
以下数据来自《宋代官制大辞典》截图:

3. 目标数据
每一行对应着一条数据。
每条数据需包括:官职/官司的名称、置废沿革、职掌沿革、官品沿革、员额、别称。
由于官职/官司的置废、职掌、品级可能经过多次变革,为了全面记录变革信息,将置废沿革、职掌沿革、官品沿革三个字段设置为数组格式进行抽取。每一次变革事件为一个字典格式数据,每个事件都具有时间属性和内容属性。
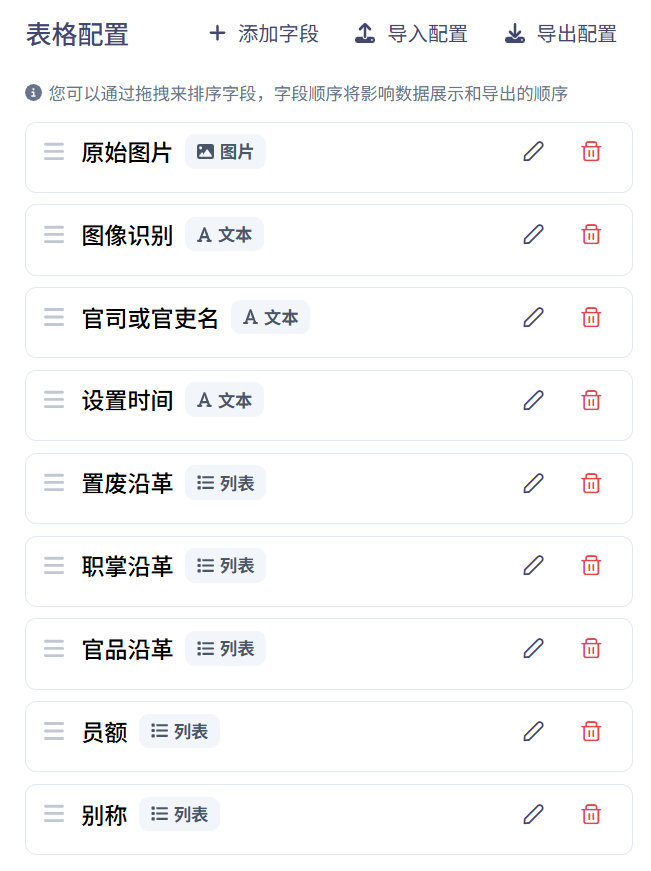
4. 表格配置
4.1 定义字段
本案例选用高级模式进行抽取,因此无需在定义字段时对字段进行描述,只需将字段抽取的规则定义清楚。
| 字段名称 | 字段描述 | 字段数据类型 |
|---|---|---|
| 原始图片 | 无 | 图片 |
| 图像识别 | 无 | 文本 |
| 官司或官吏名 | 无 | 文本 |
| 设置时间 | 无 | 文本 |
| 置废沿革 | 无 | 列表 |
| 职掌沿革 | 无 | 列表 |
| 官品沿革 | 无 | 列表 |
| 员额 | 无 | 列表 |
| 别称 | 无 | 列表 |
4.2 智能化配置
选择高级模式
定义规则:
| 序号 | 模型选择 | 模型类型 | 提示语 | 输入字段 | 智能输出字段 |
|---|---|---|---|---|---|
| 规则1 | 豆包1.5 Vision Pro 32K | 视觉模型 | 将原始图片中的内容识别为文字。要求必须从图像中逐字提取,符合原文的结构。在抽取前反思是否准确提取了文字。 | 原始图片 | 图像识别 |
| 规则2 | DeepSeek R1 | 推理模型 | 官司或官吏名:必须准确抽取,抽取之后反思是否准确抽取。没有则填无。 设置时间:该官职/官司最初设置的时间,按【朝代】+【年号】+【年份】的格式抽取。如“唐垂拱元年”,“南宋淳熙十五年”,如果没有具体年份,则只记朝代。必须准确抽取,抽取之后反思是否准确抽取。没有则填无。 置废沿革:官职/官司的设置和废置事件构成的列表,包括事件类型、时间(【朝代】+【年号】+【年份】+【日期(如有)】)、具体内容。必须准确抽取,抽取之后反思是否准确抽取。若没有则每一个属性都填写无。 职掌沿革:官职/官司职掌变革事件组成的列表。每个事件具有二个属性,第一个属性“时间”为变革发生时间(【朝代】+【年号】+【年份】+【日期(如有)】),第二个属性“职掌”为变革后职掌。必须准确抽取,抽取之后反思是否准确抽取。若没有则每一个属性都填写无。 官品沿革:官职品级变革事件组成的列表。每个事件有两个属性,第一个属性“时间”为变革发生时间(【朝代】+【年号】+【年份】+【日期(如有)】),第二个属性“品级”为变革后官职品级。必须准确抽取,抽取之后反思是否准确抽取。若没有则每一个属性都填写无。 员额:官职/官司的额定人员编制数量,不要抽取执掌的信息。列表中每对象包括以下信息:时间(【朝代】+【年号】+【年份】+【日期(如有)】)、官职名称、员额。必须准确抽取,抽取之后反思是否准确抽取。 别称:官职/官司的简称与别称组成的列表。必须准确抽取,抽取之后反思是否准确抽取。 | 图像识别 | 官司或官吏名 设置时间 置废沿革 职掌沿革 官品沿革 员额 别称 |
- 未添加示例。
Tips:
如果某字段要输入图片,该字段的数据类型应选择“图片”。
设置处理图片的规则时,应选择具有视觉能力的模型。本任务选取的是豆包1.5Vision Pro 32K模型,针对该任务效果较好。
为了防止推理模型过度思考,可以在提示词中加上“没有则填无”、“若没有则每一个属性都填写无”等提示。
为了让模型抽取更加准确,可以在提示词中加上“必须准确抽取,抽取之后反思是否准确抽取”的提示。
提示词说明抽取时间的具体格式,如“按【朝代】+【年号】+【年份】+【日期(如有)】的格式抽取”。
抽取列表格式的字段时,需要明确列表中每个元素的构成,如:“官职品级变革事件组成的列表。每个事件有两个属性,第一个属性“时间”为变革发生时间(【朝代】+【年号】+【年份】+【日期(如有)】),第二个属性“品级”为变革后官职品级”。